NextJS Blog (6)

NextJS 정적 블로그 만들기
이전에 원티드 Pre-on-Boarding에서 배운 NextJS를 좀더 활용하고자 정적인 Blog를 간단하게 만들어 보았었다. 헌데 방법을 알았다고 해서 모든걸 다 경험한것은 아닐것 같아 공부겸 조금더 다듬어 개인 Blog를 만들어 보고싶었다. 이번엔 SEO에 관해 해보았던 작업으로 웹 마스터 도구인 구글 서치 콘솔(Google Search Console)에 등록했던 방법과 sitemap.xml, robots.txt 등록에 대해 기록해둔다.
구글 서치 콘솔 등록하기
이제 어느정도 블로그위 구색이 갖추어져 있으니 내 사이트가 검색이 되도록 하기 위해서 서치 봇들이 내 블로그를 잘 읽어갈 수 있도록 등록을 해주어야 한다. 그중에서 가장 많이 사용하는 구글 서치 콘솔에 등록하면서 어떻게 구현하였는지 기록해둔다.
Google Search Console은 웹 사이트의 소유자가 Google 검색에서의 실적을 분석하여 검색 결과에 따른 개선 방식을 제안해주어 관련성이 높은 트래픽을 웹 사이트로 유도하는데 도움을 줄 수 있다.
속성 유형 선택하기
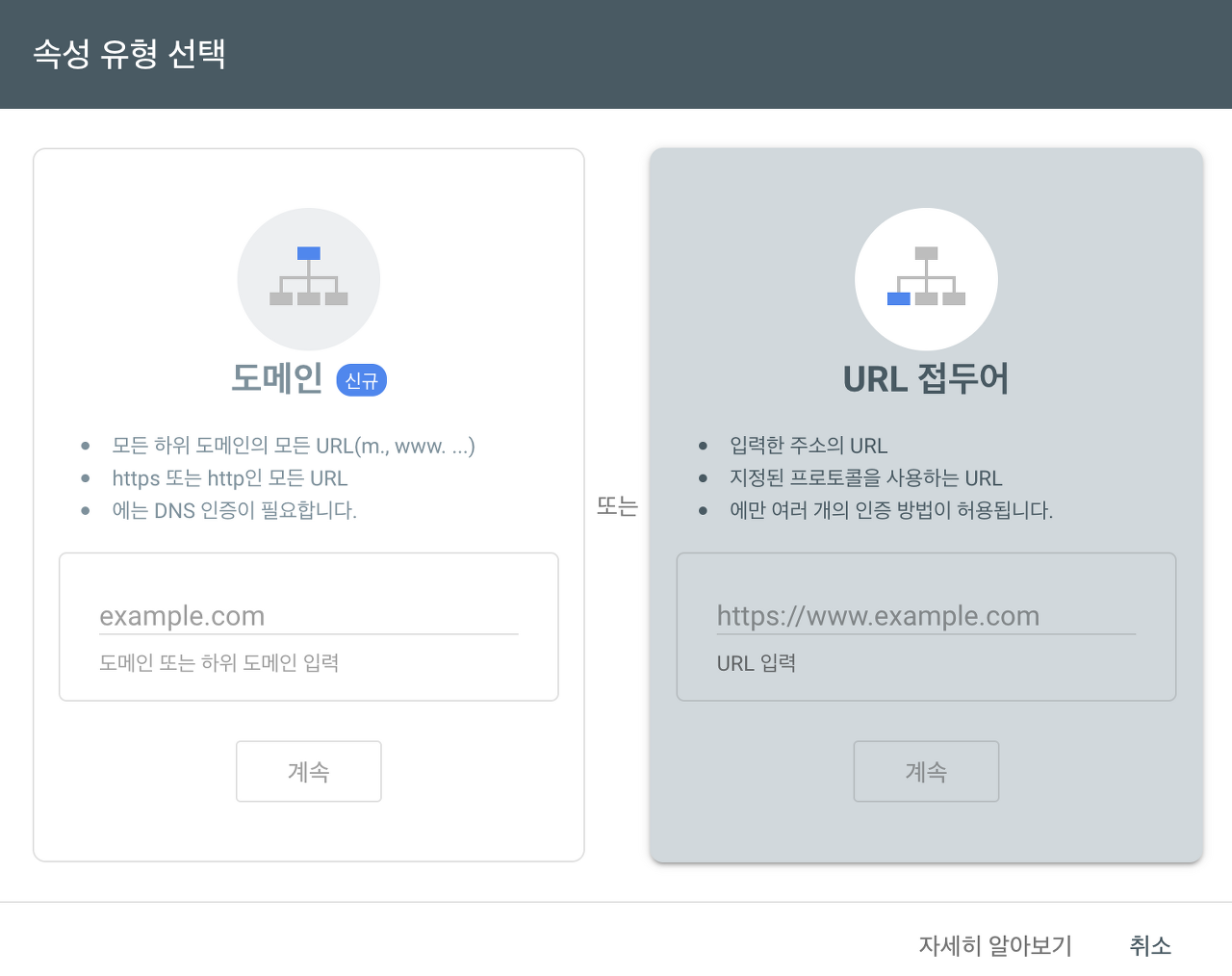
Google Search Console로 접속하여 로그인을 하면 소유권을 도메인으로 등록할지 URL로 등록할지 속성 유형을 선택할 수 있다.
도메인 소유권 등록은 도메인을 포함한 전체 소유권을 확인한다는 의미이다. example.com이라는 도메인을 가지고 있다면 하위 도메인인 a.example, b.example 등을 한번에 내 소유로 확인하게 되는 것이다.
URL 접두어 소유권 등록은 해당하는 주소에 소유권을 확인하겠다는 뜻이다. http://example.com사이트를 가지고 있다면 해당 주소에 대한 소유권을 확인하게 되고, https://example.com으로도 접속이 가능하다면 따로 등록을 해주어야 한다.
NextJS Google Meta 태그 넣기
나는 Vercel로 배포했기 때문에 간편한 URL 접두어(https://yoonhu.vercel.app)로 등록을 진행했다. 위의 URL을 입력하고 나면 HTML의 head meta태그를 추가해주어야 한다.
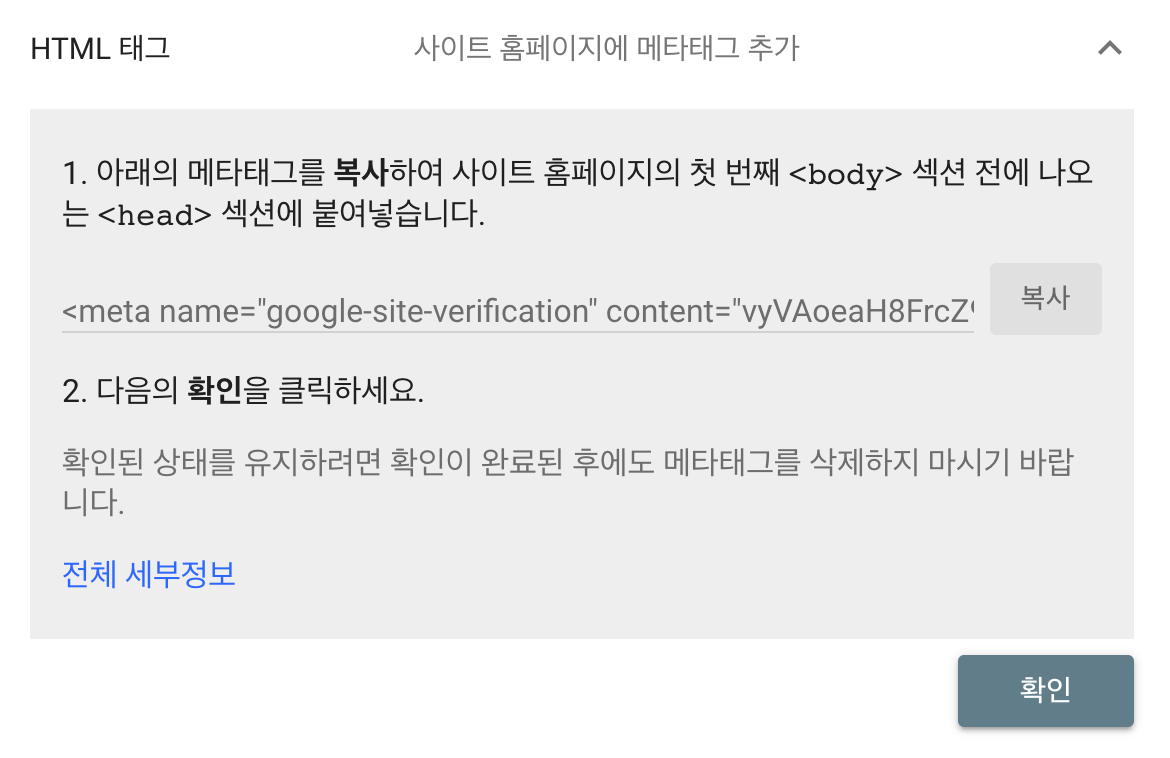
이전 블로그에서 generateMetadata를 통해 head의 meta태그를 설정해 주었다. 그렇다면 위의 서치 콘솔을 위한 태그를 추가해주면 되겠다.
// ./node_modules/next/dist/lib/metadata/types/metadata-types.d.ts/ ... export type Verification = { google?: null | string | number | (string | number)[]; yahoo?: null | string | number | (string | number)[]; yandex?: null | string | number | (string | number)[]; me?: null | string | number | (string | number)[]; other?: { [name: string]: string | number | (string | number)[]; }; };
Metadata의 타입을 찾아보니 google말고도 yahoo 등 여러 meta태그를 설정해 줄 수 있었으며 원하는 meta태그가 없더라도 other로 접근하여 만들어 넣어주면 되겠다. Google Search Console의 content값을 goole에 넣어주면 되겠다.
export const generateMetadata = async ({ params }: PostProps): Promise<Metadata> => { const { data } = await getPostData(params.slug) return { title: data.title, description: data.description, authors: { name: 'yoonhu' }, generator: 'Next.js', creator: 'yoonhu', publisher: 'Vercel', keywords: data.keywords, verification: { google: 'xxxxx' }, openGraph: { url: `https://yoonhu.vercel.app/blog/${params.category}/${params.slug}`, siteName: 'yoonhu blog', title: data.title, description: data.description, images: data.coverImage, locale: 'ko_KR', type: 'blog', authors: 'yoonhu', publishedTime: data.date, }, } }
위와 같이 넣어주고 하루정도 지나고 나면 Google Search Console에 통계가 나타나게 된다.
Sitemap.xml 만들기
SEO를 접하면서 metadata만 넘겨주면 될 줄알았던 내 짧은 지식에 한탄하며 검색해본 결과 sitemap이 SEO에 긍정적인 역할을 줄 수 있다고 하여 이에 대한 방법과 NextJS에서 어떻게 만들어 사용했는지 기록해둔다.
Sitemap
sitemap이란 웹 사이트에서 구글이나 네이버와 같은 검색 엔진에 색인할 모든 페이지를 나열한 xml파일이다. 웹 사이트에 방문하는 검색엔진 크롤러에게 지도와 같은 역할을 한다.
색인이 되어야할 모든 페이지의 목록을 제공함으로써 검색엔진 크롤러가 발견하는데 어려움을 겪는 페이지도 문제 없이 크롤링 되고 색인 될 수 있게 해주는 파일이다.
sitemap은 웹 사이트가 검색엔진에서 상위 랭킹을 차지하는데 직접적으로 영향을 주진 않지만, 검색엔진에게 웹 사이트에서 크롤링되고 색인 되어야할 중요한 페이지들에 대한 정보를 제공함으로써 크롤링 되는데 도움을 주기 때문에 결과적으로 SEO에 긍정적인 영향을 끼치게 된다.
긍정적 영향이라는 것은 사이트 맵 제출 자체가 색인을 보장하진 않는다는 뜻이다.
sitemap은 일반적으로 검색 엔진이 웹 페이지를 크롤링하여 페이지 URL을 발견하고 확인하는 메커니즘을 보완하는 것이지 크롤링을 완전히 대체하는 것은 아니다. 또한,sitemap표준을 지원하다고 해서 제출된 웹 페이지들을 모두 색인해준다는 보증이 있는것도 아니라는 것을 알아두면 좋겠다.
sitemap 형식
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"> <url> <loc>https://acme.com</loc> <lastmod>2023-04-06T15:02:24.021Z</lastmod> <changefreq>yearly</changefreq> <priority>1</priority> </url> <url> <loc>https://acme.com/about</loc> <lastmod>2023-04-06T15:02:24.021Z</lastmod> <changefreq>monthly</changefreq> <priority>0.8</priority> </url> <url> <loc>https://acme.com/blog</loc> <lastmod>2023-04-06T15:02:24.021Z</lastmod> <changefreq>weekly</changefreq> <priority>0.5</priority> </url> </urlset>
sitemap의 일반적인 형식은 위와 같다. <urlset>요소를 루트로 하고 각 페이지의 URL들은 url요소로 반복 구성되는 구조를 띄고 있다.
<url>은 페이지의 URL을 명시하는 <loc>이외에도 <lastmod>, <changefreq>,<image>, <news>, <video> 등이 올 수 있고 이를 통해 부가적인 정보를 확장할 수 있지만 검색 엔진에 따라 지원의 여부가 각자 다르다.
<loc>- 페이지의 URL을 명시한다. URL은
http:와 같이 반드시 프로토콜로 시작해야하며 웹 서버에서 요구하는 경우에는 후행 슬래쉬로 끝나야한다. 또한 최대 2,028자 미만이어야 한다.
- 페이지의 URL을 명시한다. URL은
<lastmod>- 해당 URL이 가르키는 페이지가 마지막으로 수정된 날짜이다. 이때 날짜는 W3C 날짜/시간 포멧이어야 한다.
- 날짜는
sitemap이 생성된 날짜가 아니라, 페이지가 마지막으로 수정된 날짜여야 한다.
<changefreq>- 페이지가 업데이트 되는 빈도를 명시한다. 검색엔진의 크롤링 빈도를 조정하는 힌트를 제공할 수 있지만 참고만 할뿐이다.
- Google 검색엔진은 이 값을 무시한다.
always,hourly,daily,monthly,yearly,never의 값이 올 수 있다.
<priority>- 다른 URL에 비교한 해당 URL의 상대적인 우선순위이다.
- 검색엔진에게 페이지의 중요도를 직접 알려주는 의도를 명시한다.
- Google 검색엔진은 이 값을 무시한다.
- 값은 0.0~1.0으로 지정되어야 하며, 기본 우선순위는 0.5이다. 이 수치가 검색 결과 페이지에서 노출되는 순서에 영향을 미치지는 않지만 색인 대상에 포함될 가능성을 높일 수는 있다.
Generate a Sitemap
NextJS 13에서는 app 폴더내에 Loading / Error UI를 구현하기 위한 컴포넌트를 만들때 사용했던 것처럼 Special files을 정의할 수 있다. Sitemap.xml도 마찬가지이다. app 내부에 sitemap.ts(.js)라는 Special files를 정의하게 되면 .xml파일을 자동으로 생성해주게 된다.
import { MetadataRoute } from 'next' export default function sitemap(): MetadataRoute.Sitemap { return [ { url: 'https://acme.com', lastModified: new Date(), changeFrequency: 'yearly', priority: 1, }, { url: 'https://acme.com/about', lastModified: new Date(), changeFrequency: 'monthly', priority: 0.8, }, { url: 'https://acme.com/blog', lastModified: new Date(), changeFrequency: 'weekly', priority: 0.5, }, ] }
위와 같이 설정해두면, 아래와 같은 결과를 얻을 수 있게 된다.
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"> <url> <loc>https://acme.com</loc> <lastmod>2023-04-06T15:02:24.021Z</lastmod> <changefreq>yearly</changefreq> <priority>1</priority> </url> <url> <loc>https://acme.com/about</loc> <lastmod>2023-04-06T15:02:24.021Z</lastmod> <changefreq>monthly</changefreq> <priority>0.8</priority> </url> <url> <loc>https://acme.com/blog</loc> <lastmod>2023-04-06T15:02:24.021Z</lastmod> <changefreq>weekly</changefreq> <priority>0.5</priority> </url> </urlset>
위의 sitemap 함수는 [{}]를 리턴하고 속성을 객체형태로 받아 xml형태로 만들어지는 것을 볼 수 있겠다.
이제 내가 가지고 있는 블로그의 색인이 되어야할 모든 페이지의 목록을 제공해야 하므로 위의 sitemap을 만들어 주면 되겠다. 현재 블로그가 가지고 있는 모든 경로를 하나씩 만드는것 또한 엄청난 삽질이 될것이고, 새롭게 추가된 포스팅에 대한 페이지도 등록을 해야하니 복잡한것이 이만저만 아니다.
그렇기 때문에 자동으로 맵핑해주는 함수를 만들거나, 공식문서에서 제공한 것처럼 Special files를 만들어 접근하는 것도 좋겠다.
내 경우엔 공식문서에 따른 방법대로 해보았다.
// ./app/sitemap.tsx import { MetadataRoute } from 'next' import { getCategory, getPosts } from '../../lib/ssg.module' const baseUrl = `https://yoonhu.vercel.app` const Sitemap = async (): Promise<MetadataRoute.Sitemap> => { const postData = await getPosts() const categories = await getCategory() const results: MetadataRoute.Sitemap = [] for (let i = 0; i < categories.length; i++) { const categoryPost = postData.filter((post) => post.data.category === categories[i]) results.push({ url: `${baseUrl}/${categories[i]}}`, lastModified: new Date(), }) for (let j = 0; j < categoryPost.length; j++) { results.push({ url: `${baseUrl}/${categories[i]}/${categoryPost[j].slug}`, lastModified: new Date(categoryPost[j].data.date.replace('/', ',')), }) } } return results } export default Sitemap
사실 이렇게 하는게 맞는지는 확신이 들진 않는다..😅 이중으로 for문을 돌려서 목록을 만드는데, 만약 category뿐만이 아닌 다른 경로가 생긴다면 for문이 하나 더 추가 되야할 것이다. 그렇다면 재귀함수로 구현하는것이 좀 더 알 맞은 방법이지 않을까 생각해봤다.
import { MetadataRoute } from 'next' import { getCategory, getPosts } from '../../lib/ssg.module' import { PostData } from '../../types/props' const baseUrl = `https://yoonhu.vercel.app` const Sitemap = async (): Promise<MetadataRoute.Sitemap> => { const postData = await getPosts() const categories = await getCategory() const generateSitemap = async ( baseUrl: string, postData: PostData[], categories: string[], index = 0, results: MetadataRoute.Sitemap = [] ): Promise<MetadataRoute.Sitemap> => { if (index >= categories.length) { return results } const category = categories[index] const categoryPosts = postData.filter((post) => post.data.category === category) results.push({ url: `${baseUrl}/${category}}`, lastModified: new Date(), }) for (let j = 0; j < categoryPosts.length; j++) { results.push({ url: `${baseUrl}/${category}/${categoryPosts[j].slug}`, lastModified: new Date(categoryPosts[j].data.date.replace('/', ',')), }) } return generateSitemap(baseUrl, postData, categories, index + 1, results) } return await generateSitemap(baseUrl, postData, categories) } export default Sitemap
재귀함수로 고쳐도 크게 티가 나진 않는다. 😅 아무래도 규모가 다른 사이트에 비해 그리 크지 않다보니, 이중 for를 사용해서 하는것도 좀 더 좋아 보이기도 한다.
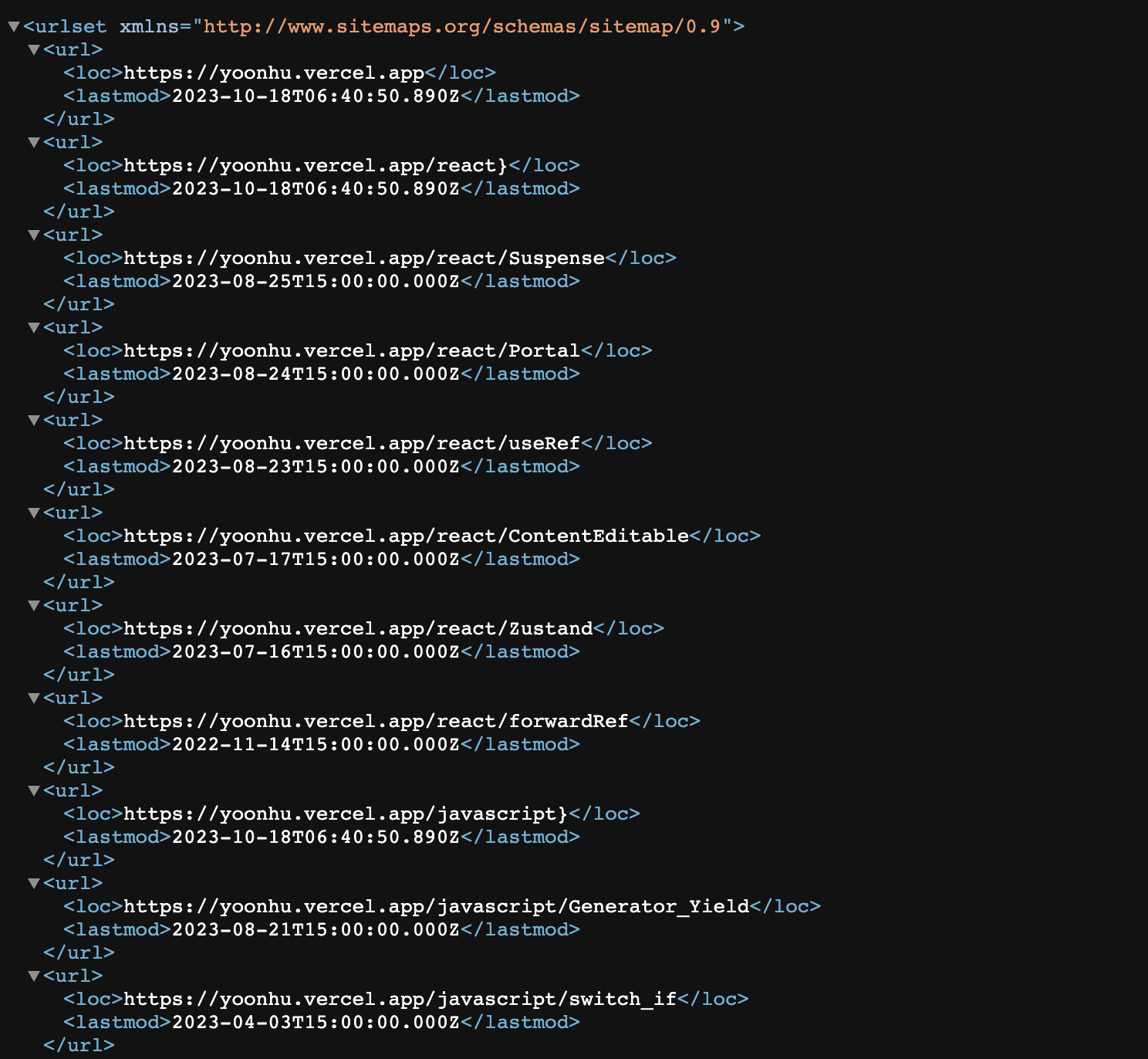
https://yoonhu.vercel.app/sitemap.xml에 들어가보면 sitemap이 잘 적용되어 있는 걸 볼 수 있다.
Robots.txt 만들기
robots.txt파일은 크롤러가 사이트에서 액세스할 수 있는 URL을 검색엔진 크롤러에 알려준다. 이 파일은 주로 요청으로 인해 사이트가 오버로드 되는 것을 방지하기 위해 사용하며 웹 페이지가 Google에 표시되는 것을 방지위한 메커니즘이 아니다.
Robots
robots.txt는 웹 사이트에 웹 크롤러 같은 로봇들의 접근을 제어하기 위한 규약이다. 크롤러는 검색엔진들의 인덱싱 목정으로 사용되는데, 웹 사이트들 입장에서도 더 많은 검색 노출을 원하는게 일반적이므로 딱히 막을 이유는 없다.
다만, 서버의 트래픽이 한정되어 있거나 검색 엔진에서의 노출을 원하지 않는 경우 이 robots.txt에 가이드 형식으로 특정 경로에 대한 크롤링을 자제해달라는 안내문을 붙이는 것과 같은 것이다.
또한, 검색엔진 크롤ㄹ러에게 사이트맵의 위치를 제공하여 웹 사이트의 콘텐츠가 검색엔진에게 더 잘 발견될 수 있도록 할 수 있다. 물론 Google Search Console과 같은 웹 마스터 도구를 이용해 사이트맵을 검색 엔진에 제출할 수 있지만, robots.txt에 사이트맵 디렉토리를 언급함으로써 사이트맵이 다른 검색 엔진 크롤러에게 빠르게 발견될 수 있다.
robots.txt는 웹 사이트의 최상위 경로(root)에 있어야 한다.
robots.txt는 사람이 아닌 검색 엔진 크롤러가 읽고 인식해야하는 파일 이기때문에 정해진 형식에 따라 작성해야한다. 가장 기본적인 형식은 아래와 같다.
#robots.txt 예시 - 기본 형식 User-agent: * Disallow: /forbidden/
robots.txt는 기본적으로 두 가지의 정보를 포함하는데, 어떤 검색엔진 크롤러를 지정할 것인디, 그리고 어떤 디렉토리를 제한할 것인지에 대한 정보를 넣을 수 있다.
- User-agent: 크롤링 규칙이 적용되어야 할 크롤러를 지정
- Allow: 크롤링을 허용할 경로
- Disallow: 크롤링을 제한할 경로
- Sitemap: 사이트맵이 위치한 경로의 전체 URL
예시
특정 크롤러의 특정 폴더 이하의 접근을 제한하는 문법
# 대상: 모든 크롤러 # 제한 디렉토리: /do-not-crawl-this-folder/ 이하 User-agent: * Disallow: /do-not-crawl-this-folder/
# 대상: 네이버 크롤러 (Yeti) # 제한 디렉토리: /not-for-naver/ 이하 User-agent: Yeti Disallow: /not-for-naver/
Generate a Robots
.txt파일이기 때문에 직접 설정하여 넣을 수도 있지만 NextJS 13에서 제공하기도 한다. robots.ts도 위의 Special files에 포함되기 때문에 sitemap을 만들었던 것과 같이 app하위에 robots.ts(.js)로 만들어 주면 되겠다.
import { MetadataRoute } from 'next' const Robots = (): MetadataRoute.Robots => { return { rules: { userAgent: '*', allow: '/', disallow: '/private/', }, sitemap: 'https://yoonhu.vercel.app/sitemap.xml', } } export default Robots
위와 같은 결과로 아래의 .txt가 만들어지게 되겠다.
User-Agent: * Allow: / Disallow: /private/ Sitemap: https://yoonhu.vercel.app/sitemap.xml

