SSR에서 React Query의 사용

React Query
이전글에서는 React Query를 시작하면서 기본적인 사용법에 대해 정리하였다. 이번엔 내가 NextJS에 적용하면서 겪은 React Query의 SSR 대해 글을 써보려고 한다.
NextJS의 가장 큰 장점은 SSR과 pre-rendering이 가능하다는 점에 큰 장점이 있는 프레임 워크이다. 이전에 React Query를 사용하지 않았을 때에는 데이터를 요청시 서버 컴포넌트에서 props로 계속해서 내려주는 방식으로 사용하였는데, 컴포넌트도 복잡해짐에 따라 props또한 계속 내려주다보니 불편한게 여간 한 두가지가 아니었다.
이러한 props drilling을 피하고 더 나은 코드를 만들고자 React Query의 Hydration을 사용해보고자 한다.
React Query의 Hydration
React Query의 Hydration은 서버에서 prefetch된 데이터 상태를 dehydrate하고, 클라이언트에서 다시 통합하거나 rehydrate하는 과정을 말한다. 이러한 과정을 통해서 사용자는 데이터 fetching을 다시 할 필요 없이 완전한 웹 페이지를 볼 수 있게 되는것이다.
NextJS의 Hydration과 같이 서버에서 fetching한 데이터의 상태를 직렬화 하고, 클라이언트에서 rehydrate하는 원리와 비슷하다. React Query는 cache를 dehydrate하여 서버에서 클라이언트로 전달하고 클라이언트에서는 dehydrate된 cache 데이터를 QueryClient로 rehydrate하여 사용한다.
이후 추가적인 네트워크 요청이 있을때 해당 데이터를 반환하면서 불필요한 네트워크 요청을 없앨 수 있게 되며, 이에 따른 로드타임 개선, 불필요한 로딩 상태 및 콘텐츠 깜빡임 등의 문제를 해결할 수 있다.
사용
자 위에서 아무리 글로 좋은 글을 적어봤자 실제로 해보는것보다야 기억에 잘 남지 않는다. 바로 실전으로 들어가보자. 먼저 Next.js를 사용하고 있으니, 웹 서버의 캐싱을 위한 fetch에 대해 알아보고, 이후에 React-query를 사용한 캐싱을 알아보도록 하겠다.
Next.js fetch
Next.js에서는 fetch를 이용한 캐싱을 사용한다. Next.js의 fetch는 아래와 같이 설명하고 있다. (Next.js 13이상의 App Router 기준으로 설명하겠다.)
Next.js는 서버에서 각 요청이 고유의 지속적인 캐싱 및 재검증 의미를 설정할 수 있도록 네이티브 웹 fetch() API (opens in a new tab)를 확장했다. 이 확장을 통해 cache는 서버 측 fetch 요청이 프레임워크의 지속적인 데이터 캐시와 어떻게 상호 작용할지를 나타냅니다. 서버 컴포넌트 내에서 async와 await을 사용하여 fetch를 직접 호출할 수 있습니다.
현재 글에서는 React-query에 관한 글이기 때문에 Next.js의 캐싱에 관한 자세한 설명은 하지 않겠다. 다만 웹 서버의 캐싱을 위한 fetch option에 간단하게만 보고 요청을 만들어서 사용해 보겠다. 공식문서를 번역한 Next.js 한글문서 (커뮤니티)를 참고해서 보자면 아래와 같다.
-
options.cache
Next.js 데이터 캐시와의 상호 작용 방식을 설정한다.
fetch(`https://...`, { cache: 'force-cache' | 'no-store' })- no-store (기본값): Next.js는 캐시를 확인하지 않고 매 요청마다 원격 서버에서 리소스를 가져오며, 다운로드한 리소스로 캐시를 업데이트하지 않는다.
- force-cache: Next.js는 데이터 캐시에서 일치하는 요청을 찾는다.
- 일치하는 항목이 있고 신선한 경우, 캐시에서 반환된다.
- 일치하는 항목이 없거나 오래된 경우, Next.js는 원격 서버에서 리소스를 가져와서 다운로드한 리소스로 캐시를 업데이트한다.
- 알아두면 좋은 점: Next.js에서
no-cache옵션은no-store와 동일하게 동작한다.
-
options.next.revalidate
fetch(`https://...`, { next: { revalidate: false | 0 | number } })- 리소스의 캐시 수명을 설정한다(초 단위).
- false : 리소스를 무기한 캐시한다. 의미적으로
revalidate: Infinity와 동일하다. HTTP 캐시는 시간이 지남에 따라 오래된 리소스를 제거할 수 있다. - 0 : 리소스가 캐시되지 않도록 한다.
- number : (초 단위) 리소스가 최대 n초 동안 캐시되어야 함을 지정한다.
- 알아두면 좋은 점:
- 개별
fetch()요청이 경로의 기본 revalidate 값보다 낮은 revalidate 숫자를 설정하면 전체 경로 재검증 간격이 감소한다. - 동일한 경로의 두 fetch 요청이 서로 다른 revalidate 값을 가지는 경우, 더 낮은 값이 사용된다.
- 편의상, revalidate를 숫자로 설정하면 cache 옵션을 설정할 필요가 없다.
{ revalidate: 3600, cache: 'no-store' }와 같은 상충되는 옵션은 오류를 발생시킨다.
- 개별
-
options.next.tags
fetch(`https://...`, { next: { tags: ['collection'] } })- 리소스의 캐시 태그를 설정한다. 데이터는
revalidateTag를 사용하여 온디맨드로 재검증할 수 있다. 사용자 지정 태그의 최대 길이는 256자이고 태그 항목의 최대 수는 64개이다.
- 리소스의 캐시 태그를 설정한다. 데이터는
-
예제
export default async function Page() { // 이 요청은 수동으로 무효화될 때까지 캐시되어야 합니다. // `getStaticProps`와 유사합니다. // `force-cache`가 기본값이므로 생략할 수 있습니다. const staticData = await fetch(`https://...`, { cache: 'force-cache' }) // 이 요청은 매 요청마다 다시 가져와야 합니다. // `getServerSideProps`와 유사합니다. const dynamicData = await fetch(`https://...`, { cache: 'no-store' }) // 이 요청은 10초 동안 캐시되어야 합니다. // `revalidate` 옵션이 있는 `getStaticProps`와 유사합니다. const revalidatedData = await fetch(`https://...`, { next: { revalidate: 10 }, }) return <div>...</div> }
서버 컴포넌트에서 fetch 사용하기
먼저 위에서 설명한 tag, revalidate를 사용하기 위한 fetch 함수를 래핑하여 아래와 같이 만들었다. 필자는 데이터를 가져올때 타입을 확장해서 사용하고 있는데, 여기서는 간단한 예제로만 dataFetch 함수를 만들도록 하겠다.
import { MESSAGES } from '@/constants/messages' export const dataFetch = async <T>(url: string, tags?: string[]): Promise<T | undefined> => { try { const response = await fetch(url, { next: { tags, revalidate: 60 * 60, }, }) const result = await response.json() if (!response.ok) { console.error(MESSAGES.ERROR.DATA_FETCH_ERROR) return } return result } catch (error) { console.error('dataFetch error', error) } }
이후 각 페이지에서 사용될 action을 만들어 래핑해서 사용하였다. 필자는 fetch에 사용되는 revalidateTag를 react-query에서 사용한 Key와 동일하게 사용하여 데이터를 관리하는게 편하다고 생각하여 아래와 같이 만들었다.
export const getTodo = async (id: string) => { const url = TODO_API.GET_TODO(id) const data = await dataFetch<ITodo>(url, queryKeys.todo(id)) return data?.data }
여기에서 사용된 queryKeys는 아래에서 정의해서 사용하도록 하겠다.
React Query Provider 설정
이전글에서 ReactQueryProvider를 만들면서 QueryClient객체를 서버의 상태 따로, 클라이언트의 상태 따로 만들어둔것을 기억할 것이다.
import { QueryClient, isServer, QueryCache } from '@tanstack/react-query' export const defaultStaleTime = 60 * 1000 function makeQueryClient() { return new QueryClient({ defaultOptions: { queries: { staleTime: defaultStaleTime, }, }, queryCache: new QueryCache({}), }) } let browserQueryClient: QueryClient | undefined export function getQueryClient() { if (isServer) { return makeQueryClient() } if (!browserQueryClient) browserQueryClient = makeQueryClient() return browserQueryClient }
데이터 충돌 방지와 캐시 오염, 상태 관리의 복잡성 증가, 성능 저하, 캐시 비효율성 이슈를 해결하기 위해서다. 이를 Layout에 감싸서 사용하자.
import ReactQueryProvider from '@/utils/ReactQueryProvider' export default function RootLayout({ children, }: Readonly<{ children: React.ReactNode }>) { return ( <html lang="en"> <body> <ReactQueryProvider>{children}</ReactQueryProvider> </body> </html> ) }
queryKey, queryFn 정리하기
API를 서비스별로 관리하면 가독성과 유지 보수에 유리한 이점을 가져갈 수 있다. 나는 Todo이라는 서비스 API를 가지고 설명해 보도록 하겠다.
// @/services/Services.ts import axios, { AxiosInstance } from 'axios' class Service { protected http: AxiosInstance constructor() { this.http = axios.create({ baseURL: process.env.NEXT_PUBLIC_API_URL, headers: { 'Content-Type': 'application/json', }, }) } } export default Service
먼저 TodoService 클래스를 구현하기 전, Http요청을 처리하는 레이어를 구현하기 위해 간단하게 위와 같이 Service class를 구성하였다. 이후 각각의 서비스를 클래스에서 Service 클래스를 상속받아 처리하면 되겠다.
import Service from '../Services' class TodoServices extends Service { async getTodo(id: string) { const { data } = await this.http.get(TODO_API.GET_TODO(id)) return data } async getTodos(params: queryParams) { const { data } = await this.http.get(TODO_API.GET_TODOS(params)) return data } } const todoServices = new TodoServices() export default todoServices
이후 queryKey와 queryFn을 효율적으로 관리하기 위해서 TkDodo's blog에서 React Query Key 관리하는 방법을 참고로 아래와 같이 따로 관리해 두었고, 버전이 업데이트 되면서 각각의 query의 option을 따로 관리할 수 있는 객체로 만들어줄 수 있게 되었다. (queryOptions)
import todoServices from './todoServices' import { queryOptions, infiniteQueryOptions } from '@tanstack/react-query' export const queryKeys = { todo: (id: string) => ['todo', id] todos: ['todos'] } export const queryOptions = { todo: (id: string) => queryOptions({ queryKey: queryKeys.todo(id), queryFn: () => todoServices.getTodo(id), }), todos: () => infiniteQueryOptions({ queryKey: queryKeys.todos, queryFn: ({ page }: { page: number }) => todoServices.getTodos({ page }), initialPageParam: 1, getNextPageParam: (lastPage) => { const currentPage = lastPage.meta.currentPage const totalPages = lastPage.meta.totalPages return currentPage >= totalPages ? null : currentPage + 1 }, }), }
참고했던 블로그에서는 queryKey에 관해서만 이야기하지만, SSR에서의 Hydrate를 사용한다거나, useQuery로 해당 함수를 불러오는 경우가 많아져 queryKeys와 비슷하게 queryOptions으로 함수도 같이 관리하기로 하였다.
또한, 클라이언트에서 useQuery를 사용해서 데이터를 가져올때, 좀 더 사용하기 편하도록 각각을 hooks로 만들어 따로 관리하도록 한다.
// @/hooks/useTodo.ts export const useTodo = (id: string) => { return useQuery(queryOptions.todo(id)) } // @/hooks/useTodos.ts export const useTodos = () => { return useInfiniteQuery(queryOptions.todos()) }
서버에서 prefetching 하고 데이터 de/hydrate하기
이제 React Query Hydration을 위한 준비가 끝났다. prefetch를 하고 싶은 페이지에서 React query를 날려보도록 하자.
useQuery, useInfiniteQuery 데이터 prefetch하기
export interface TodoPageProps { params: Promise<{ id: string }> //15.0.3 기준 Promise<{ id: string }>로 사용. } const TodoPage = async ({ params }: TodoPageProps) => { const { id } = (await params).id const queryClient = getQueryClient() const todo = await getTodo(id) // 단일 query 데이터 미리 가져오기 방법 1 queryClient.setQueryData(queryKeys.todo(id), todo) // 단일 query 데이터 미리 가져오기 방법 2 await queryClient.prefetchQuery(queryOptions.todo(id)) // 무한 스크롤 쿼리 데이터 미리 가져오기 await queryClient.prefetchInfiniteQuery(queryOptions.todos()) const dehydratedState = dehydrate(queryClient) return ( <HydrationBoundary state={dehydratedState}> <Todo /> </HydrationBoundary> ) } export default TodoPage
위의 TodoPage는 서버 컴포넌트로 이루어져 있다. 여러 블로그에서는 Next.js의 서버 컴포넌트는 API요청을 병렬로 처리한다고 이야기 하고 있지만, 나는 사실 해당 부분을 공식 문서에서 찾아볼 수 없었다. 하여 여러 비동기 요청이 있을 경우에는 Promise.all을 사용해서 병렬로 처리하는게 좋을 것 같다. 위의 예시에서는 방법1과 방법2 두 가지를 나눠 설명하기 위해 Promise.all을 사용하지 않았다.
먼저 방법1에 대해서 살펴보자.
-
방법1 : setQueryData 사용하기
첫 번째 방법은 해당 데이터를 queryClient의
setQueryData를 사용하여 데이터를 캐싱하는 방법이다. Next.js는 fetch를 통해서 데이터를 가져오고 캐싱하게 된다. dataFetch 함수에서 fetch의 옵션으로next: { revalidate: 60 * 60 }을 설정하여 해당 페이지의 데이터를 캐싱하여 60분 동안 유지되게 하였다. 즉, 해당 페이지를 구성하는데 사용되는 데이터의 유효기간을 60분으로 설정한 것이다. 사실 해당 데이터도 클라이언트에서 사용하는 데이터와 다름 없다. 그렇기에queryClient.setQueryData를 사용하여 데이터를queryClient객체에 저장하고dehydrate를 사용하여 직렬화 후 클라이언트에서 사용할 수 있도록 하는 것이다.queryClient.getQueryData를 사용하여 데이터를 가져올 수도 있지만, 필자의 경우에는 주로useQuery나useSuspenseQuery를 사용하여 해당 데이터 캐시에 접근하여 사용한다. gcTime / staleTime를 사용하여 최신 데이터로 업데이트 할 수 있도록 할 수 있다는 장점이 있기 때문이다. 만약 해당 데이터가 잘 바뀌지 않는 데이터라고 하면,getQueryData를 사용하여 데이터를 가져오는게 좋겠다. -
방법2: prefetchQuery 사용하기
두 번째 방법으로는
queryClient.prefetchQuery를 이용하는 방법이다. 해당 요청은 만들어둔queryOptions.todo(id)를 사용하여 API 요청을 보내고, 데이터를 받아와 prefetch한다. 이후 방법1과 마찬가지로 데이터를queryClient객체에 저장하고dehydrate를 사용하여 직렬화 후 클라이언트에서 사용할 수 있도록 한다.하지만 여기에는 함정이 있다. 바로
queryOptions.todo(id)를 사용한다는 것이다. Next.js의 fetch는 실용적이게도 해당 요청을 캐싱해두어 같은 엔드포인트의 요청이 있을경우 캐싱된 데이터를 반환하여 불필요한 네트워크의 요청을 줄인다. 하지만, 위에서 설정한queryOptions.todo(id)는 axios를 이용한 요청으로 동일한 요청에 대해서 별도로 처리하게 된다. 따라서 동일한 엔드포인트에 대해 두 번의 API 요청이 일어나게 되는것이다. 즉, 페이지를 구성하는 데이터는 한번의 요청으로 처리되지만 클라이언트로 직렬화하여 내려주기위한 데이터, prefetch하는 데이터는 같은 데이터지만 따로 네트워크 요청이 들어가게 되는 것이다. 이렇게 되면 Next.js에서 사용하는 fetch의 캐시가 무용지물이 되어 버린다.해당 문제를 해결하기 위해서는 방법1과 같이 fetch를 사용한 데이터를
setQueryData를 사용하거나, fetch를 사용하겨 같은 API요청으로 처리하도록 유도하면 되겠다.const TodoPage = async ({ params }: TodoPageProps) => { const { id } = (await params).id const queryClient = getQueryClient() await queryClient.prefetchQuery({ queryKey: queryKeys.todo(id), queryFn: () => getTodo(id), }) const dehydratedState = dehydrate(queryClient) return ( <HydrationBoundary state={dehydratedState}> <Todo /> </HydrationBoundary> ) }설정했을 경우 fetch로 cache hit 되면 아래와 같이 콘솔에 출력된다.
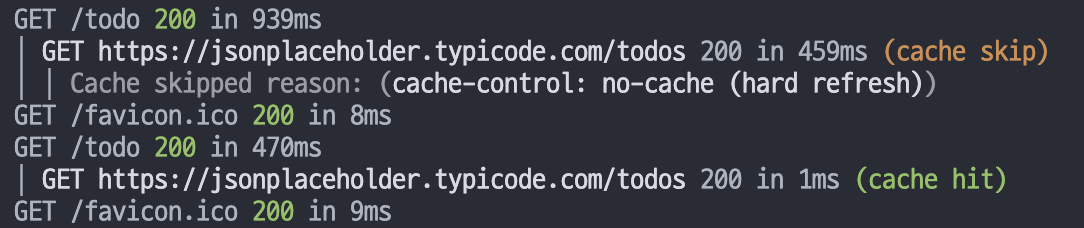
만약 방법2를 그대로 사용했을 경우 아래와 같이 cache skip / hit 조차 뜨지 않는 것을 볼 수 있다.


해당 fetch가 cache hit 되는지 알아보기 위해서 next.config.js에서 아래와 같이 설정해주면 된다.
const nextConfig = { logging: { fetches: { fullUrl: true, }, }, } -
무한 스크롤 쿼리 데이터 미리 가져오기
React-query는 무한 스크롤 구현을 위한 prefetch도지원하고 있다.
queryClient.prefetchInfiniteQuery를 사용하여 데이터를 미리 가져와 캐시에 저장해두고 사용자 즉, 클라이언트에서 구현되는 무한스크롤 페이지 데이터를 먼저 받아와 사용하게 되면서 사용자 경험을 증가시킬 수 있다.const Todo = () => { const { data, fetchNextPage, hasNextPage } = useTodos() const todoList = data.pages.flatMap((page) => page.data) return ( <InfiniteScroll dataLength={todoList.length} next={fetchNextPage} hasMore={hasNextPage} loader={<></>}> {todoList.map((todo) => ( <TodoCard key={todo.id} todo={todo} /> ))} </InfiniteScroll> ) }
